








Motivation
Transformer-based generative language models have recently gained widespread attention due to their exceptional performance across various natural language tasks. These models power applications ranging from generating content, translating languages, analyzing sentiment, and powering chatbots and virtual assistants. Despite their remarkable capabilities, adopting these models raises significant privacy concerns. Individuals and organizations may share private or sensitive data with these systems, whether by transcribing conversations or providing private classifications. As these models become increasingly integrated into human lives, they frequently process sensitive information such as names, addresses, credit card details, or even financial and healthcare data. The challenge becomes even more pressing with the growing demand for personalized AI agents that adapt to individual preferences and workflows. To deliver customized outputs, these agents require continuous access to sensitive user data, such as personal habits or speech patterns. While this enhances utility, it also creates significant risks of data breaches or unauthorized access.
Privacy-enhancing technologies (PETs) such as secure multiparty computation (MPC) are essential for enabling privacy-preserving machine learning (PPML). In the most prominent setting, a model provider possesses a proprietary model and aims to provide it as a service to clients for use with their private data without gaining any knowledge about the model. At the same time, the model provider does not learn anything about clients’ input. Several MPC systems leverage linear secret sharing schemes as they allow linear operations to be performed with a small running time overhead. Regardless, when evaluating large language models (LLMs) with multiple layers, these overheads add up, requiring extensive GPU acceleration to remain competitive. Also, PPML approaches often suffer from reduced accuracy in models requiring multiple nonlinear computations.
LLMs consist of several layer types such as embedding, layer normalization, attention, and multilayer perceptron. The computation required for these layers can be broken down into linear operations, mainly matrix multiplications, and nonlinear operations such as inverse square root, softmax, and activation functions like GeLU. Linear operations can be computed via Beaver triples. On the other hand, nonlinear layers involve large lookup tables or expensive approximations that also reduce accuracy.
Let’s take a look at the example:
To increase efficiency while maintaining privacy, split inference emerged as a practical approach that divides the computation between an edge device and a server. In this method, part of the model is evaluated on the edge device until a cutoff layer, which is the output of a hidden layer. Once the server receives the cutoff layer, it finishes evaluating the model while learning minimal information about the raw inputs since it only sees the intermediate results. This method also limits the amount of computation the edge device has to do and offloads the work to a more powerful server. However, the cutoff layer and the model evaluation can still leak a great deal of information, even though the raw input data are not revealed. There have been many proposed successful attacks that reconstruct the input data or gain meaningful information from split inference techniques
Considering these vulnerabilities, we introduce Fission to mitigate the limitations of prior approaches. Fission is a hybrid privacy-preserving compute framework that utilizes MPC nodes for linear operations as well as additional nodes that we call evaluators to speed up the computation of nonlinear functions.
The Fission Framework

To evaluate a non-linearity, the MPC parties shuffle the output of each matrix multiplication and reveal parts of the shuffled output to the evaluator parties E1, . . . , EN to compute the non-linearity in the clear. Next, all the outputs are secret shared between the MPC nodes that unshuffle to the correct order. The patterned boxes represent secret shares (owned by MPC parties), while the solid boxes represent values in the clear owned only by one evaluator.
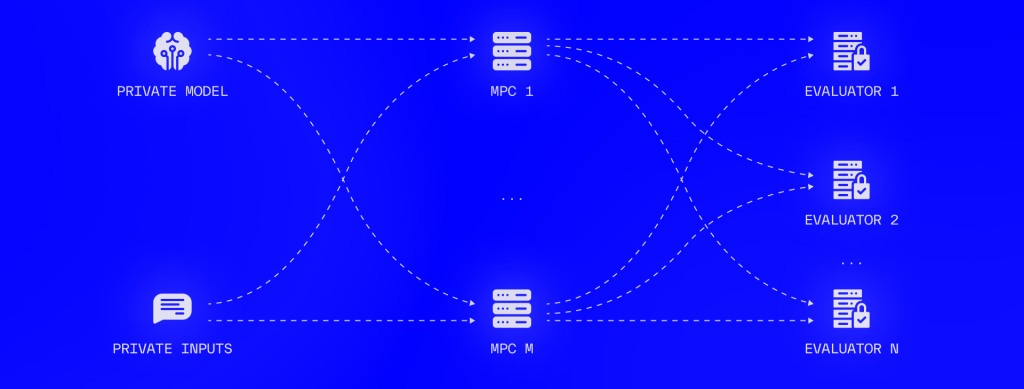
Fission architecture overview consisting of an MPC cluster of M nodes and a cluster of N evaluators.
Results
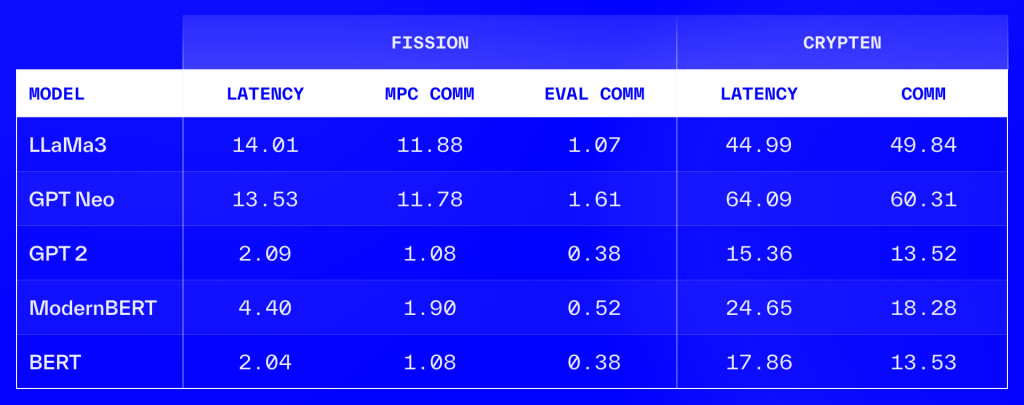
We compared Fission running times against Crypten for various LLMs with sequence lengths 256. We ran LLaMA 3 1B, GPT Neo 1.3B, GPT2, ModernBERT and BERT models. We also reported latency in seconds and communication in GBs. Then, we split the communication for Fission into MPC communication and evaluator communication. We observed that Fission is 3 to 8 times faster than Crypten.
Conclusion
While split inference offers a compelling approach to model evaluation, it suffers from critical privacy shortcomings. Conversely, PETs provide strong security guarantees, often at the expense of a significant computational overhead. To reconcile these tradeoffs, we present Fission, a framework that evaluates linear layers under MPC and nonlinear layers in the clear using a separate evaluator network. Fission’s hybrid design enables private, highly accurate, and performant LLM inference.
References
- Cabrero-Holgueras, Mouris, Vega. “Rethinking the Future of Secure Computation” Nillion.com, 24 Jan 2025, https://nillion.com/news/rethinking-the-future-of-secure-computation
- Mouris, Dimitris. “Unlocking a New Era of Private AI for Everyday Use” Nillion.com, 22 November 2024, https://nillion.com/news/unlocking-a-new-era-of-private-ai-for-everyday-use
- Ugurbil, Mehmet, et al. Fission: Distributed Privacy-Preserving Large Language Model Inference. 2025, https://eprint.iacr.org/2025/653. Code available at https://github.com/jimouris/curl
- Knott, Brian, et al. “Crypten: Secure Multi-Party Computation Meets Machine Learning.” Advances in Neural Information Processing Systems (NeurIPS), 2021, https://arxiv.org/pdf/2109.00984. Code available at https://github.com/facebookresearch/CrypTen
- Santos, Manuel B., et al. “Curl: Private LLMs through Wavelet-Encoded Look-Up Tables.” Conference on Applied Machine Learning for Information Security (CAMLIS), 2024, https://eprint.iacr.org/2024/1127.pdf. Code available at https://github.com/jimouris/curl
- Gouert, C., et al. “Ripple: Accelerating Programmable Bootstraps for FHE with Wavelet Approximations.” Information Security. ISC 2024. Lecture Notes in Computer Science, vol. 15257, edited by N. Mouha and N. Nikiforakis, Springer, 2024, https://doi.org/10.1007/978-3-031-75757-0_14. PDF at https://eprint.iacr.org/2024/866.pdf. Code available at https://github.com/NillionNetwork/ripple
- Zheng, F., et al. Permllm: Private Inference of Large Language Models within 3 Seconds under WAN. 2024, arXiv preprint arXiv:2405.18744, https://arxiv.org/pdf/2405.18744. Attacks code available at https://github.com/NillionNetwork/permllm_attacks